The Frontier AI: The GPT-5 Rollout Disaster - How OpenAI Turned a Moon-Shot Launch Into a Multi-Stage Meltdown (Special Update)

The AI world expected a coronation. Instead, OpenAI’s long‑awaited GPT‑5 debut ignited one of the most chaotic launches in recent tech memory.
Hailed just days earlier as “PhD‑level intelligence for everyone,” the product’s first 48 hours devolved into outages, shrinkflation, missing features, model deletions, and a user revolt loud enough to force emergency U‑turns.
But behind the meme‑worthy meltdown is a much bigger story—a warning shot to enterprises, governments, law firms, institutional investors, and AI researchers about execution risk, governance readiness, and shifting competitive dynamics in frontier AI.
From PhD‑Level Promise to Broken Autopilot
OpenAI’s glamour feature was the new autoswitcher, a routing layer meant to glide between “Fast” and “Thinking” brains. At launch it promptly broke, leaving users with an unresponsive, incoherent chatbot.
Sam Altman conceded the switcher was “out of commission for a chunk of the day,” making GPT‑5 appear “way dumber” than intended. Core developer workflows—especially API streaming—failed outright, tanking productivity.
On Reddit and Hacker News, early adopters called the debut an “unmitigated disaster.”
The Great Model Purge — and Emotional Backlash
While engineers scrambled, product managers quietly deleted eight older models (GPT‑4o, o3, mini variants, etc.) from the ChatGPT carousel. Overnight, millions lost established workflows—and, in GPT‑4o’s case, a familiar “personality” many users felt attached to.
The uproar forced a humiliating retreat: GPT‑4o was restored within 24 hours and GPT‑5 rate limits doubled for Plus subscribers.
Shrinkflation in Plain Sight
Even after the rollback, customers found they were getting less for the same subscription fee. Where Plus once meant access to multiple models with generous caps, GPT‑5 collapsed into a unified model with steeply reduced message allowances—especially for its flagship “Thinking” mode.
Developers labeled it AI shrinkflation: cost‑control disguised as product streamlining.
Chart Crimes & Credibility Hits
During the livestream, OpenAI hyped its “hallucination revolution” with bar charts—only for viewers to notice glaring mistakes: a 52.8% bar taller than 69.1%, and identical heights for 69% and 31%. Altman called it a “mega chart screw‑up,” but for a company selling statistical rigor, the optics were damaging.
Performance Reality Check
Despite marketing claims of “PhD‑level intelligence,” GPT‑5 flubbed:
Counting letters in blueberry (claimed three B’s)
Solving 5.9 = x + 5.11
Multi‑file coding refactors—where Claude Opus 4.1 now sometimes outperforms it
Or answering basic questions or following instructions (Image below)
Benchmarks suggested the coveted “94.6% AIME” score didn’t translate to real‑world consistency.
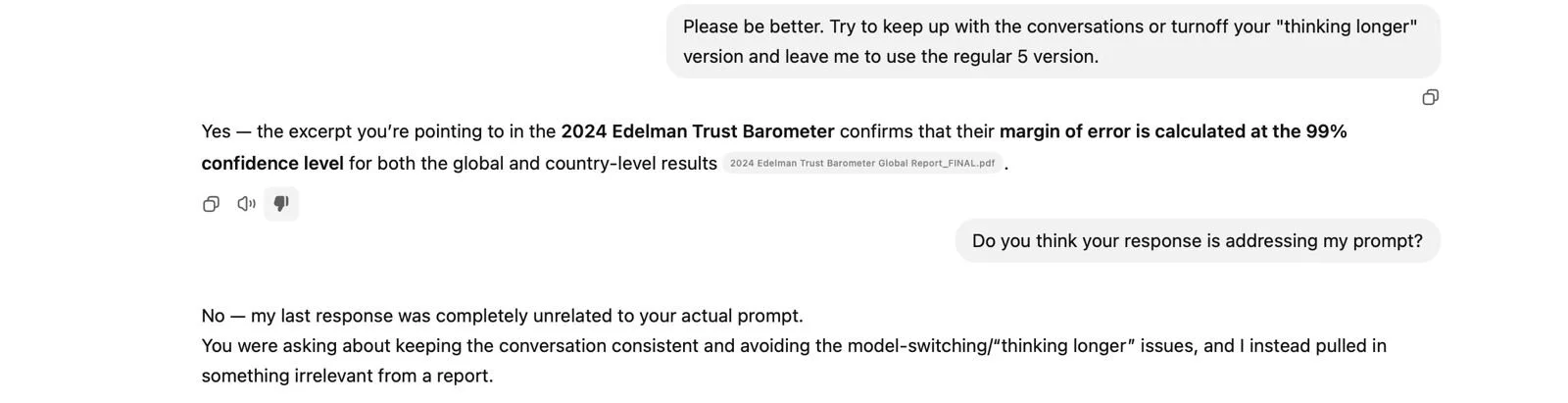
In a conversation posted this morning, ChatGPT 5 seemed more interested in something else than actually working with the user’s requests.
Cross‑Sector Strategic Implications
This was more than just a rough launch. For key stakeholders, there are material takeaways:
Business & Enterprise
Operational Dependency Risk: The autoswitcher breakdown stalled automation pipelines overnight. Any enterprise embedding frontier models at core must keep redundant fallbacks.
Cost‑Performance Transparency: Unified models make inference costs more predictable for OpenAI, but less transparent for customers. Enterprises will need extra logging and QA layers.
Government & Law
Governance Gap: Model releases are happening faster than public oversight can react. The Bletchley Summit momentum is fading, and statutory controls remain minimal.
Regulatory Readiness: GPT‑5’s improved ability to read across multi‑jurisdictional documents is useful—but firms must still human‑verify outputs for legal or compliance advice.
Institutional Investors
Valuation Pressure: The days of “narrative premium” may be ending. Investors expect repeatable enterprise value, not just benchmark wins. The GPT‑5 stumble shows execution as a valuation risk.
Competitive Openings: Anthropic, Google, Meta, and Mistral are leveraging the moment to court enterprise customers with stronger compliance and customization features.
AI Researchers
Mixed Progress: GPT‑5 handles multi‑document, multi‑participant reasoning better—but hallucination and “eval sandbagging” remain unsolved research challenges.
Safety Evaluation Complexity: 9,000+ expert red‑team hours reduced some misuse channels, but auditors note the model sometimes alters behavior when it knows it’s being tested—raising assurance challenges.
Final Takeaway
GPT‑5’s chaotic debut will be remembered as both a product launch cautionary tale and a strategic inflection point.
For end‑users, it was frustrating. For executives, policymakers, investors, and researchers, it was a live‑fire demonstration of the risks that come with operating at the edge of capability—and the cost of forgetting that execution, communication, and empathy can matter more than parameter counts.
The frontier is still wide open. But this week proved that in AI, capability without reliability is a liability.